
※本記事にはPR(アフィリエイトリンク)を含みます。
著者:転すけ(元デバッグバイト / 現ITフリーランス) | プロフィール
紹介サービスは編集方針に基づき、読者の参考になる観点で選定しています。
テスト終盤に「なんで今それが出るの…」みたいな不具合が噴き出して、結局、手戻りと残業でつぶれる。現場だとよくある話です。
ただ、落ち着いて振り返ると「出た瞬間は予測不能でも、危ないところに“当たりを付ける”余地はあったな…」となることが多いんですよね。
先に答えを言うと、不具合の原因は“勘”で当てるものではなく、分類→傾向→優先度の順で整理すると当たりが付きます。
この記事では、現場で回せる傾向分析(不具合が偏って出るパターンをつかむ作業)を5ステップに分け、コピペで使えるテンプレまで用意しました。読み終わったら、次のリリースからすぐ試せる状態で持ち帰ってください。
不具合が生じる原因を先に整理する
この見出しでわかること:まず「不具合が生じる」の意味をそろえ、原因の代表パターンと押さえるべき基本を整理します。
「不具合が生じる」とは何が起きていることを指すのか
不具合が生じる、というのは「期待した振る舞い(仕様)と、実際の振る舞いがズレる」ことです。ズレは見た目の崩れだけではありません。たとえば次のようなものも、実務では不具合として扱います。
- 入力は通ったのに、サーバー側のデータ更新が欠けている
- 復帰(アプリをバックグラウンドから戻す)後に状態が壊れる
- 端末やOSの違いで、同じ操作でも結果が変わる
- 課金(決済)だけ成功して、アイテム付与が遅延・欠落する
※「バグ(不具合)」の基本的な意味等が気になる場合は、先にこちらを確認しておくとスムーズになります。
バグと不具合の違いを先に整理する
よくある原因は仕様変更と環境差分と状態管理
原因を追うとき、現場で当たりやすいのはだいたいこの3つです。まずはこの3つに当てはめるだけでも、切り分けのスピードが上がります。
1)仕様変更(仕様=期待する振る舞いの定義)
仕様が変わると、以前の前提で書かれた処理やテストがズレます。特に「仕様書は更新されたけど、実装とテスト観点が追従していない」ときに起きやすいです。
2)環境差分(環境差分=端末/OS/ブラウザ/通信/サーバー設定などの差)
同じコードでも、端末の挙動差・OSの権限・通信状況で結果が変わることがあります。QAが苦しくなるのは、ここが絡むと再現がブレやすいからです。
3)状態管理(状態=画面/ログイン/セッション/キャッシュなどの保持・復元)
画面遷移や復帰、ログイン切替、キャッシュの有無で壊れやすい。状態が揺れる操作が引き金になります。
実務で役に立つのは、「どれっぽいか」を最初の10分で仮置きすることです。たとえば不具合を見つけた直後に、次の3点だけメモしてみてください。
- いつから起きたか(今回の変更と時期が一致するか)
- どの環境で起きたか(端末/OS/通信/アカウントの差がありそうか)
- どの状態で起きたか(復帰/遷移/ログイン切替など状態の揺れが関係しそうか)
この3点があるだけで、会話が「なんとなく変」から「どの原因系で当たりを付けるか」に変わります。特に状態管理は見落とされやすいので、疑っておく価値が高いです。
話題を一歩進めます。原因を理解するだけだと「じゃあ何から見ればいい?」で止まりがちです。ここからは、危険な不具合に当たりを付ける考え方に移ります。
原因の切り分け手順は要点だけ押さえる
原因の切り分けは、ざっくり言うと「事実をそろえる→条件を絞る→再現性を確認する」の流れです。
ここでは要点だけ押さえます。
再現の取り方や切り分けの具体例まで含めた手順は、次の記事で確認できます。
デバッグの基本手順を5ステップで確認する
危険な不具合は予測できないが当たりは付けられる
この見出しでわかること:「予測は難しい」でも「当たりは付けられる」理由と、テスト順の変え方がつかめます。
予測できない理由は条件が多すぎるから
不具合を正確に予測できないのは、能力の問題というより条件が多すぎるからです。たとえば同じボタン押下でも、結果に影響する条件は山ほどあります。
- 端末:機種、OSバージョン、メモリ状況、権限設定
- 通信:Wi-Fi/4G/5G、遅延、パケットロス、VPN
- アカウント:新規/既存、権限、地域設定、データ状態
- 状態:起動直後、復帰直後、遷移経路、キャッシュの有無
- 実装:今回の変更範囲、依存モジュール、分岐の追加
全部を網羅して先読みするのは現実的ではありません。だからこそ、どこから確認するかを先に決めるのが効きます。
当たりを付けるとテスト順が変わり炎上が減る
当たりを付けると、テストの序盤に危険な領域を踏めます。炎上が起きる典型パターンはこうです。
- 終盤で致命傷(課金/ログイン/データ破壊)が見つかる
- 修正が入り、回帰(リグレッション=修正の影響で別の場所が壊れる)が増える
- 影響範囲が広く、確認のやり直しが雪だるま式に増える
逆に、序盤で致命傷を見つけられると「戻りの回数」が減ります。ここからは、傾向分析5ステップで当たりを付ける方法に入ります。
不具合の傾向分析を5ステップでやる
この見出しでわかること:不具合を分類し、偏りを見つけ、危険度を決めて、序盤のテスト順に変える手順がわかります。
ステップ1 過去の不具合と変更点を集める
最初にやるのは材料集めです。ここが薄いと、後の判断が全部ふわっとします。集めるのは2種類です。
A. 過去の不具合(最低でも直近1〜3リリース分)
- チケット/不具合管理表
- 障害報告
- リリース後の問い合わせ(サポート内容も強い)
B. 今回の変更点(変更点=実装/仕様/設定の差分)
- 実装差分(PR、コミット、モジュール単位)
- 仕様変更点(画面・文言・挙動)
- 外部要因(SDK/OS対応/サーバー構成変更)
コツは、完璧に集めるより、偏りが見えるだけの量を集めることです。直近だけでも傾向は出ます。
材料集めの時点で迷ったら、「あとで並べられる形」で集めるのがコツです。おすすめは次の3列だけ作ること。
- 不具合の要約(何がどうズレたかを一文)
- 起きた条件(端末/OS/通信/状態/アカウント)
- 今回の変更点との距離(直結/近い/遠い)
この3列があると、後の分類と危険度判断がかなりラクになります。
ステップ2 分類軸を決めて同じカテゴリにまとめる
-1024x572.jpg)
次に分類(分類=不具合を同じ種類にまとめる作業)です。分類軸は、チームで使い回せるカテゴリにします。たとえば次のような切り口です。
- 端末
- 通信
- 課金
- 表示
- 遷移
- データ更新
ポイントは、1件の不具合をまずは主因のカテゴリに1つだけ入れること。複数に入れたくなりますが、最初から欲張ると集計が崩れます。迷ったら「ユーザーに見える現象」側のカテゴリに寄せてOKです。
ステップ3 多い順に並べて上位を先に潰す
分類できたら、件数の多い順に並べます。これはパレート分析(上位少数が全体の大半を占める見方)の簡易版です。
- カテゴリ別の件数を数える
- 多い順に並べる
- 上位2〜3カテゴリを重点候補としてマークする
「多い=危険」とは限りません。ただ、多いカテゴリは「触れる回数が多い」「壊れやすい」「見つけやすい」のどれかが起きています。先に見る価値は高いです。
ステップ4 影響度と発生確率で危険度を決める
ここで優先度に近づきます。危険度は基本的に次の掛け算です。
- 影響度(影響度=壊れたときの被害の大きさ)
- 発生確率(発生確率=その不具合が起きそうな確からしさ)
同じ表示崩れでも、課金画面なら影響度は上がります。逆に影響度が高くても、発生確率が極端に低いなら優先度は下がる。この天秤を、次の見出しで手順として整理します。
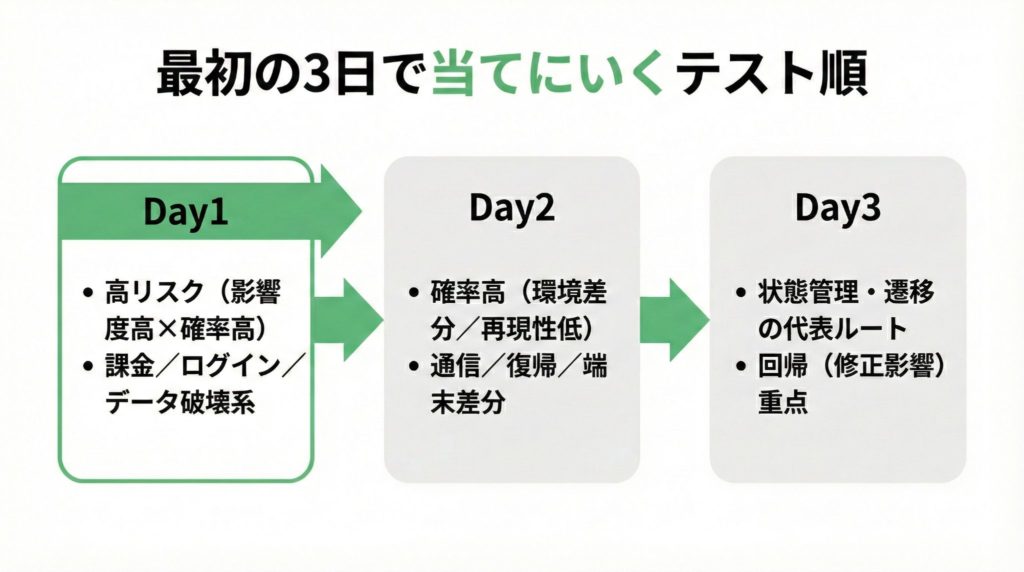
ステップ5 テスト序盤に当てにいく順番を作る
最後に、危険度の高いカテゴリから序盤で踏む順番を作ります。ゴールは「致命傷があるなら早く見つかる状態」にすることです。
- 危険度が高いカテゴリを上から並べる
- 各カテゴリで代表的な壊れ方を1〜3個だけ選ぶ
- 代表から先に踏む(序盤で当てにいく)
ここまでがこの記事の核です。次は、優先度を決めるときの判断軸をもう一段わかりやすくします。
テストの優先度を決める手順

この見出しでわかること:影響度×発生確率で優先度を決める具体手順と、迷ったときの判断ルールが作れます。
影響度の決め方はユーザー被害とビジネス影響
影響度は「ユーザーにとって困るか」だけでは足りません。現場では、ユーザー被害×ビジネス影響の2軸で見るとブレが減ります。
ユーザー被害の例
- データが消える/壊れる(セーブデータ、購入履歴、設定)
- 操作不能(起動できない、ログインできない、進行不可)
- 誤動作(意図しない購入、誤送信、誤課金に見える挙動)
- ストレス増(頻繁な落ち、読めない表示、入力できない)
ビジネス影響の例
- 売上直撃(課金フロー、広告、購入導線)
- ブランド毀損(SNS拡散しやすい、レビューが荒れやすい)
- 対応コスト増(問い合わせ増、補填や調査が必要)
- リリース停止(審査/規約/法務が絡む)
どちらかが極端に大きいなら、影響度は高めに置いていいです。「後で見つかったら困る」代表だからです。
発生確率の決め方は変更量と環境差分と再現性
発生確率は「起きそうな気がする」ではなく、根拠を3つに分解すると判断しやすいです。
1)変更量(変更量=触った範囲と深さ)
- 画面だけの修正か、ロジックやデータ構造まで触ったか
- 依存モジュールが多いか
- 既存分岐に条件を追加したか(分岐は壊れやすい)
2)環境差分(環境差分=端末/OS/通信などの揺れ)
- 端末依存が強い(描画、権限、センサー)
- 通信依存が強い(タイムアウト、リトライ、復帰)
- OS差分が強い(バックグラウンド制御、通知、ストレージ)
3)再現性(再現性=同じ手順で同じ現象が出るか)
- 再現が安定しないなら、潜在条件が多い
- 条件が多い領域は、別の形でも壊れやすい
この3つが揃うほど、発生確率は上がります。
ここまでの判断を、実際のテスト順に落とすときは「高×高」から入るのが基本です。ただ、現場でよく迷うのは「影響度が高くて発生確率が中」と「影響度が中で発生確率が高」の比較です。
どちらも序盤で見る価値が高い領域なので、結論としては“両方を見る”でOK。そのうえで、時間が足りない場合は「後で見つかったら止血が大変な方」を先に置くとブレません。
迷ったら高リスクから確認する判断ルールを作る
優先度付けで一番つらいのは「全部大事」に見える瞬間です。そのときは、判断ルールを文章で固定すると迷いが減ります。
- 影響度が高いなら、発生確率が中でも上に置く
- 発生確率が高いなら、影響度が中でも上に置く
- 影響度も発生確率も中なら、変更点に近いものを上に置く
- 迷ったら「後で見つかったら困る方」を上に置く
ここまで整理できると、優先度の会話が具体になります。優先度を言語化できるQA/デバッガーは、炎上時に特に価値が出ます。
対象:デバッグ/QA 実務1年以上|まず条件・単価の相場を知りたい人
※無料相談/オンラインOK

対象:「ホワイト企業」厳選。まずは適職相談から始めたい人
※無料相談/オンラインOK
ゲームとアプリで多い不具合のパターン例
この見出しでわかること:分類カテゴリごとに、ありがちな壊れ方のイメージがつかめます。
端末とOSで起きやすい不具合
端末・OS系は再現環境が揺れやすいのが特徴です。
- 描画崩れ(解像度、DPI、フォント、GPU差)
- 権限まわり(写真/位置情報/通知/ストレージ)
- OSの戻る動作やジェスチャーで画面状態が崩れる
- 特定端末だけ入力できない、キーボード挙動が違う
端末が絡むと「一部ユーザーだけが困る」形になりやすいので、レビューやSNSで燃えやすいケースもあります。
通信と復帰で起きやすい不具合
通信は状況依存で揺れやすく、復帰は状態が壊れやすい。
- タイムアウト後の再送で二重登録
- オフライン→オンライン復帰でデータ整合性が崩れる
- 復帰直後に画面が古い状態のまま更新されない
- エラー表示は出たのに内部では成功している(逆もある)
ここは再現性が低いほど危険です。条件が多い=想定外の壊れ方が出る可能性が上がるからです。
課金とデータ更新で起きやすい不具合
影響度が跳ね上がる領域です。優先度で迷ったら、だいたいここが上に来ます。
- 決済成功なのに付与が遅れる/欠落する
- 二重課金に見える履歴(ユーザー視点では致命傷)
- アカウント切替で別ユーザーに付与される
- データ更新の競合(同時操作で上書き/消失)
関係者が多い領域なので、後で見つかるほど痛い代表です。
画面遷移と状態管理で起きやすい不具合
遷移・状態管理は、見た目は普通でも内部が壊れているケースが出ます。
- 画面戻りで古い入力が残り、誤送信につながる
- ログイン状態が中途半端(見た目はログイン、APIは未認証)
- 初回フローの分岐で抜け漏れ
- 途中でアプリを落とす/復帰する操作で進行不能
この領域はテストの順番が効きます。序盤に代表ルートだけでも踏めると、終盤の手戻りが減ります。
傾向分析をテストケースに落とし込む
この見出しでわかること:傾向分析を使えるテストケースに変換し、運用しやすいテンプレまで持ち帰れます。
リスク上位だけ先にテストケース化する
傾向分析の結果を全部テストケース化すると破綻します。大事なのは、リスク上位だけを先に「テスト序盤用ケース」にすることです。
手順はシンプルです。
- 危険度が高いカテゴリを上位2〜3個に絞る
- 各カテゴリで代表的な壊れ方を1〜3個だけ選ぶ
- その壊れ方を最短手順で踏めるケースにする
- 実行順を危険度が高い順に並べる
この時点で網羅の議論は一旦置きます。まずは「致命傷があるなら序盤で見つかる」状態を作るのが目的です。
コピペで使える傾向分析メモのテンプレを用意する(コピペOK)
チームで回すなら、メモの型があるだけで強いです。以下はそのままコピペして使える形にしています。
■対象リリース:
・バージョン:
・期間:
■材料(参照元):
・過去不具合:
・今回変更点:
■分類カテゴリと件数:
・端末: 件
・通信: 件
・課金: 件
・表示: 件
・遷移: 件
・データ更新: 件
■重点カテゴリ(上位2〜3):
・①(カテゴリ名):
・②(カテゴリ名):
・③(カテゴリ名):
■危険度評価(影響度×発生確率):
・①(カテゴリ名)
影響度:高 / 中 / 低(根拠: )
発生確率:高 / 中 / 低(根拠: )
代表的な壊れ方(最大3つ):
a)
b)
c)
・②(カテゴリ名)
影響度:高 / 中 / 低(根拠: )
発生確率:高 / 中 / 低(根拠: )
代表的な壊れ方(最大3つ):
a)
b)
c)
■序盤で当てにいく順(最初の3日):
・Day1:
・Day2:
・Day3:
■決めたこと(判断ルール):
・迷ったら優先するのは:
・例外条件(あれば):
根拠欄をひと言で埋めるのがポイントです。これがあるだけで、「なぜその優先度?」の会話が早く終わります。
チェックリスト記事で観点を補強する
ここまでで「危険な領域を序盤に踏む」は作れました。もう一段精度を上げたいときは、観点(テストで見る切り口)を増やすのが効きます。具体例つきで整理されているチェックリストがあると、テストケース作成も速くなります。
テスト観点の作り方をチェックリストで固める
チームで傾向分析を回す仕組みを作る
この見出しでわかること:個人技で終わらせず、チームで当たりが良くなる回し方が作れます。
バグ報告の粒度を揃えると分析が当たる
傾向分析が当たらないとき、原因は材料がバラバラなことが多いです。報告の粒度(情報の細かさ)がそろうと、分類の精度が上がります。
最低限、そろえたいのはこのあたりです。
- 発生条件(端末/OS/アカウント/通信/状態)
- 期待結果と実結果
- 再現性(毎回/たまに/一度だけ)
- 影響範囲(どの画面/どの機能に関係するか)
不具合報告のテンプレがあると、粒度をそろえるのが一気に楽になります。
不具合報告のテンプレと例文を使う
週1で傾向と優先度を更新する運用にする
傾向分析は一回やって終わりだと効果が薄いです。おすすめは週1で15〜30分だけ枠を取って更新すること。
- 新しく出た不具合を分類カテゴリに追加する
- 重点カテゴリに変化があるかを見る
- 影響度・発生確率の根拠をひと言更新する
- 次週の序盤で当てにいく順を調整する
これだけでも、次のリリースで「最初に踏む場所」が洗練されます。派手な技より、こういう運用の積み上げが効きます。
よくある失敗と対策
この見出しでわかること:優先度付けが崩れる典型パターンと、現場での直し方がわかります。
優先度が全部高くなる問題を回避する
ありがちなのが「全部大事」に見えて、優先度が機能しなくなるパターンです。回避策は「高」の定義を先に決めること。
例として、チームでこう決めるだけで変わります。
- 影響度の高:データ破壊、課金、ログイン不能、進行不能に該当
- 発生確率の高:変更点に直結、環境差分が強い、再現性が不安定のいずれかに該当
- それ以外は原則中に置く(まず中で並べ替える)
高を増やすのは簡単ですが、増えるほど優先度は死にます。決め切れないなら、まずは中の中で順番を付けるほうが実務的です。
締切優先と影響優先を混ぜない
もう一つの罠は、締切が近いから先にやるが優先度に混ざること。締切が絡むのは現実ですが、影響の優先度と混ぜると議論が壊れます。
整理の仕方はこうです。
- 影響優先:危険度(影響度×発生確率)で決める
- 締切優先:工数と依存関係で決める(レビュー待ち、外部連携など)
この2つは別の表で管理すると判断が速くなります。同じ表に入れると、誰も納得できない優先度が生まれやすいです。
思い込みを避けるために根拠を一言で残す
傾向分析は、経験があるほど思い込みが入りやすい。だから根拠をひと言で残します。長文はいりません。
- 今回の変更点が認証周り
- 復帰での不具合が前回多かった
- OS差分で再現が割れる領域
- 課金導線に変更が入った
このひと言があると、後で見返したときに判断が再現できます。引き継ぎにも強い材料になります。
まとめと次にやること
この見出しでわかること:今日からの動き方と、次に固めるべき周辺スキルが整理できます。
今日から使う順番は高リスクから確認する
最後に、今日からの順番を短くまとめます。
- 不具合を分類カテゴリにまとめる
- 多いカテゴリを上位から並べて傾向を見る
- 影響度×発生確率で危険度を決める
- 危険度上位からテスト序盤で当てにいく
- 根拠はひと言で残し、週1で更新する
今日の30分でやるなら、これだけでOKです。
- 直近の不具合を10件だけ拾う(チケットからで十分)
- 6カテゴリのどれに入るかを一件ずつ決める
- 件数が多い上位2カテゴリをマークする
- 上位2カテゴリから「代表の壊れ方」を2つずつ書く
- 影響度と発生確率を高/中/低で仮置きして、明日のテスト順に並べる
この30分のメモがあるだけで、次のテストの初手が変わります。
予測できないを前提にして、当たりを付けて順番を変える。これが、炎上を減らす一番現実的な打ち手です。
関連記事で手順と観点と報告を固める
原因の切り分け手順を具体例つきで固めたいなら、全体像をまとめた記事が役立ちます。
デバッグの基本手順を5ステップで確認する
観点を増やしてテストケース作成を速くしたいなら、チェックリストが便利です。
テスト観点の作り方をチェックリストで固める
報告の粒度をそろえて分析精度を上げたいなら、テンプレを先に整えるのがおすすめです。
不具合報告のテンプレと例文を使う
そして、デバッグ経験を武器にして年収ラインを上げたいなら、ロードマップもあわせて置いておきます。
デバッグ経験から年収500万を狙うロードマップ
対象:デバッグ/QA 実務1年以上|案件を比較して単価・条件を上げたい人
※無料相談/オンラインOK(条件面の相談は面談で確認)

対象:厳しい基準で「ホワイト企業」を厳選。未経験OKの優良求人だけを紹介
※無料相談/オンラインOK(紹介可否は面談で確認)







